0x00 前言
百度网盘最近推出了一个垃圾文件清理功能,可以扫描重复的文件,就试了一下。扫描结果发现存在许多的重复文件,删除后空间可以再多一个T。就想删除一下,结果需要开通会员。于是就想着来实现一下如何快速删除网盘重复的文件。
要实现这个功能,第一首先要知道重复的文件,第二就是对这些重复的文件进行删除了。
0x01 如何获取重复的文件
这里以wap版为例。
打开https://pan.baidu.com/wap/home 并抓包。
可以看到一个Get请求
1
| https://pan.baidu.com/api/list?bdstoken=***********&web=5&app_id=250528&logid=MTQ5NTYxMjU1OTQ1NDAuOTE2MjI3ODg0NjE5MTU0Ng==&channel=chunlei&clienttype=5&order=time&desc=1&showempty=0&page=1&num=20&dir=%2F
|
主要请求参数:
| 参数名 |
备注 |
| bdstoken |
网页源代码中有 |
| loginid |
BASE64(时间戳+四位+.+16位数字),固定值即可 |
| page |
页码 |
| num |
每页显示条数 |
| dir |
文件路径 |
| order |
排序的条件(固定时间排序即可) |
| desc |
升序降序(降序排列即可) |
其他参数固定值即可
返回内容为JSON
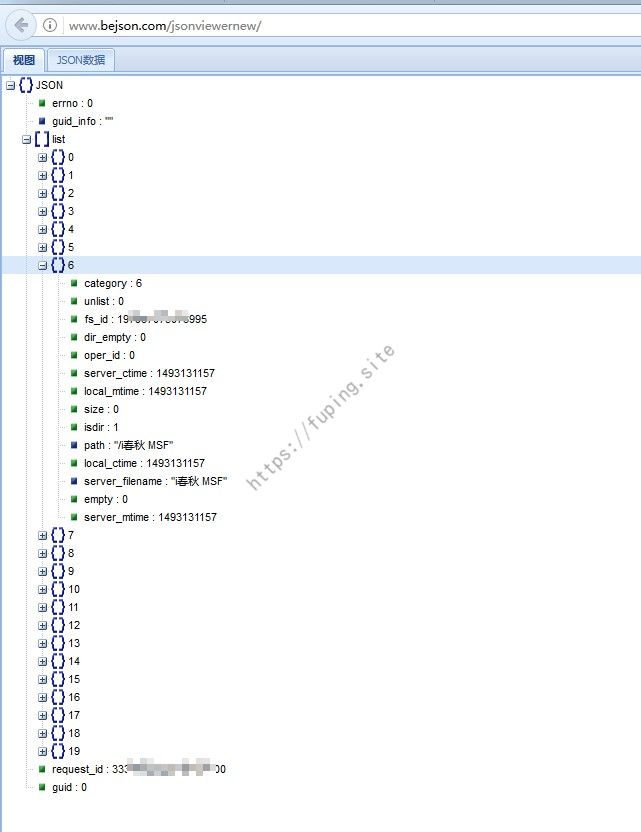
当遇到文件时,会返回文件的MD5和大小以及路径。
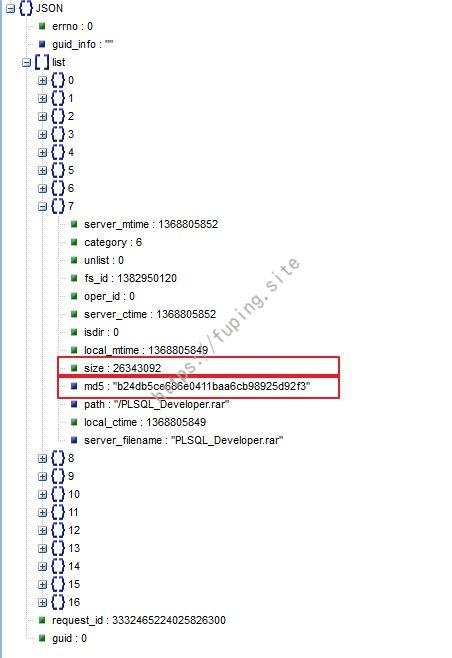
返回JSON中的主要内容说明
只列举需要的字段
| 名称 |
含义 |
备注 |
| isdir |
是否为目录 |
文件为0,目录为1 |
| size |
文件大小 |
单位是字节 |
| md5 |
文件的MD5值 |
可以用来判断文件是否重复 |
| path |
文件的路径 |
包含文件名 |
| server_filename |
文件名称 |
文件的名称 |
于是可以根据文件的MD5值来判断文件是否重复。
首先将文件的主要信息(如MD5、大小、路径、名字)等信息保存到数据库中。然后根据MD5来判断是否重复,将重复的文件列出来,最后就是删除了。
这里采用的开发语言是Java,Http请求采用了jsoup,处理Json采用了FastJson。数据库采用了MySQL。
因为主要是为了分享思路,所以只贴部分代码了,知道怎么实现这个流程,代码写起来就简单许多了,实现的语言也就多样化了。
具体实现步骤如下:
1.获取bdstoken
访问https://pan.baidu.com/wap/home ,查看源代码搜索bdstoken即可看到。
代码的实现如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
public static String getbdstoken(){
String bdstoken = null;
Document doc = getDoc(Util.URL_HOME,getCookies());
String regex = "\"bdstoken\":\"(.*)\",\"quota";
Pattern pattern = Pattern.compile(regex);
Matcher matcher = pattern.matcher(doc.html());
if(matcher.find()){
bdstoken = matcher.group(1);
}
return bdstoken;
}
|
Cookie只需要两个内容,一个是BDUSS,另一个是STOKEN。
1
2
3
4
5
6
7
|
public static Map<String,String> getCookies(){
Map<String,String> cookies = new HashMap<String, String>();
cookies.put("BDUSS", "你的BDUSS");
cookies.put("STOKEN", "你的STOKEN");
return cookies;
}
|
2.递归获取所有的文件,并将文件的相关内容保存到数据库中
获取每页文件内容时需要三个参数:当前页面、每页显示数量和路径。
如下代码所示:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
public static List<PanFile> getFiles(int page,int num,String dir){
String url = "https://pan.baidu.com/api/list?bdstoken="+getbdstoken()+"&web=5&app_id=250528&logid=MTQ5NTQxMzA2Njg4ODAuODE0NzYwMjEyMzAzOTY5Mg==&channel=chunlei&clienttype=5&order=time&desc=1&showempty=0&page="+page+"&num="+num+"&dir="+dir;
String jsonStr = getbody(url, getCookies());
JSONObject jsonObj = JSONObject.parseObject(jsonStr);
JSONArray result = jsonObj.getJSONArray("list");
List<PanFile> files= JSON.parseArray(result.toJSONString(),PanFile.class);
return files;
}
|
递归遍历当前路径下所有文件代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
|
public static void printFiles(String str){
boolean flag=false;
String dency[] = {"/C#资料/我的c#","/12-19 Java Workplace","/dumppp","/myWEB"};
for (String string : dency) {
if(str.trim().equals(string)){
flag = true;
}
}
if(!flag){
try {
str = URLEncoder.encode(str, "utf-8");
} catch (UnsupportedEncodingException e) {
e.printStackTrace();
}
List<PanFile> files= UtilMethod.getFiles(1,2000,str);
for (PanFile panFile : files) {
if(panFile.getIsdir()==1){
printFiles(panFile.getPath());
}else{
String fileName = panFile.getPath();
System.out.println(fileName+"---size:"+panFile.getSize()+"--md5:"+panFile.getMd5());
insertDB(panFile.getServerMtime(),panFile.getCategory(),panFile.getFsId(),panFile.getIsdir(),
panFile.getServerCtime(),panFile.getLocalMtime(),panFile.getSize(),panFile.getMd5(),
panFile.getPath(),panFile.getLocalCtime(),panFile.getServerFilename());
}
}
}
}
|
效果如图所示
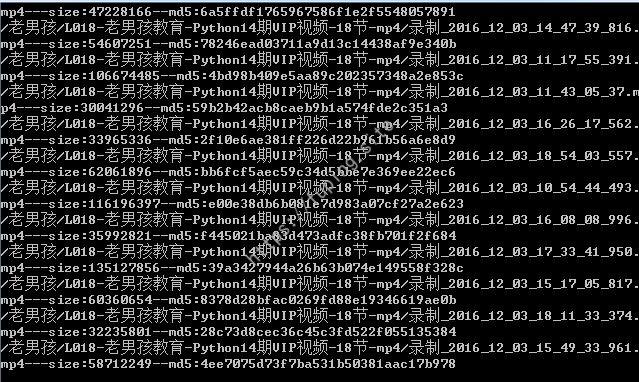
查看数据库中的文件信息
由于有些目录下面是代码,而且文件多有小,所以就不针对这些文件目录下的文件进行遍历。就采用了白名单的方式,对白名单中内容不遍历。
由于某些路径中含有其他字符,导致找不到路径,使用采用了URL编码。
为了方便,直接将page设置为1,num值换为2000(可以根据自己的文件多少来调节,最好大一些),一页就将所有的数据显示出来。
插入数据库方法的代码比较简单,这里就省略了。
3.获取重复的大文件
已经将文件的信息都存储在数据库中,然后根据数据库中文件的MD5来获取重复的文件。我这里只把大于500M的重复文件给列举出来。
1.获取大于500M的重复文件的MD5
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
|
public static List<String> setp1(){
List<String> ltMd5 = new ArrayList<String>();
String sql = "select count(*),md5,server_filename from mmpan "
+ "where size > 1024*1024*500 "
+ "group by md5 "
+ "HAVING COUNT(md5) >1 "
+ "order by path";
Connection conn = DBFactory.getConnection();
PreparedStatement pst = null;
ResultSet rst = null;
try {
pst = conn.prepareStatement(sql);
rst = pst.executeQuery();
while(rst.next()){
ltMd5.add(rst.getString("md5"));
}
} catch (SQLException e) {
e.printStackTrace();
}finally {
DBFactory.close(rst, pst, conn);
}
return ltMd5;
}
|
2.根据步骤1获取文件的MD5值,获取最小path的长度
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
|
public static int setp2(String md5){
int length = -1;
String sql = "select min(LENGTH(path)) from mmpan where md5=?";
Connection conn = DBFactory.getConnection();
PreparedStatement pst = null;
ResultSet rst = null;
try {
pst = conn.prepareStatement(sql);
pst.setString(1, md5);
rst = pst.executeQuery();
if(rst.next()){
length = rst.getInt(1);
}
} catch (SQLException e) {
e.printStackTrace();
}finally {
DBFactory.close(rst, pst, conn);
}
return length;
}
|
3.根据MD5和最短路径,列出大于最短路径的文件
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
|
public static List<String> setp3(String md5,int length){
List<String> ltPath = new ArrayList<String>();
String sql = "select path from mmpan where md5=? and LENGTH(path) > ?";
Connection conn = DBFactory.getConnection();
PreparedStatement pst = null;
ResultSet rst = null;
try {
pst = conn.prepareStatement(sql);
pst.setString(1, md5);
pst.setInt(2, length);
rst = pst.executeQuery();
while(rst.next()){
ltPath.add(rst.getString(1));
}
} catch (SQLException e) {
e.printStackTrace();
}finally {
DBFactory.close(rst, pst, conn);
}
return ltPath;
}
|
获取这个列表是为了将其删除
将以上三步综合起来,如下
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
public static List<String> getPaths(){
List<String> ltPath = null;
List<String> ltPaths = new ArrayList<String>();
List<String> lt = UtilMethod.setp1();
int length = -1 ;
for (String md5 : lt) {
length = UtilMethod.setp2(md5);
ltPath = UtilMethod.setp3(md5, length);
for (String path : ltPath) {
ltPaths.add(path);
}
}
return ltPaths;
}
|
此时列表中的文件都是为了删除的文件的路径。
0x02 如何实现删除文件
删除文件时抓包,发现如下请求
1
2
3
4
5
6
7
8
| POST /api/filemanager?opera=delete&async=2&channel=chunlei&web=1&app_id=250528&bdstoken=****&logid=MTQ5NTU0ODk4Mjk2MjAuMzgyNjczNDYzNDM0MTU0NA==&clienttype=0 HTTP/1.1
Host: pan.baidu.com
X-Requested-With: XMLHttpRequest
Cookie: Cookie
Connection: close
Content-Length: 61
filelist=%5B%22%2F000%2F%E7%A4%BE%E5%B7%A5%E5%BA%93.rar%22%5D
|
所需参数有bdstoken和删除文件的列表
我们首先将需要删除文件拼接起来
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
| /**
* 根据文件路径拼接filelist
* @return
*/
public static String getFileList(){
List<String> ltPath = UtilMethod.getPaths();
StringBuilder sb = new StringBuilder();
sb.append("[");
for (int i = 0; i < 3; i++) {
//System.out.println(ltPath.get(i));
sb.append("\"");
sb.append(ltPath.get(i));
sb.append("\"");
sb.append(",");
}
sb.append("***]");
return sb.toString().replace(",***", "");
}
|
为了测试,我仅仅先删除三条进行测试。如果需要全部删除,将3换成ltPath.size()即可。
删除文件的代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
public static String delRequest(String filelist){
String url = "https://pan.baidu.com/api/filemanager?opera=delete&async=2&channel=chunlei&web=1&app_id=250528&bdstoken="+getbdstoken()+"&logid=MTQ5NTU0ODk4Mjk2MjAuMzgyNjczNDYzNDM0MTU0NA==&clienttype=0";
String result = "删除失败,请重试";
String jsonStr = getbody(url, getCookies(),filelist);
JSONObject jsonObj = JSONObject.parseObject(jsonStr);
if(jsonObj.get("errno").toString().equals("0")){
result = "文件删除成功,删除成功的文件为"+filelist;
}
return result;
}
|
测试删除的代码如下:
1
2
3
4
5
6
| @Test
public void testdelFile(){
String fileList = UtilMethod.getFileList();
System.out.println(UtilMethod.delRequest(fileList));
}
|
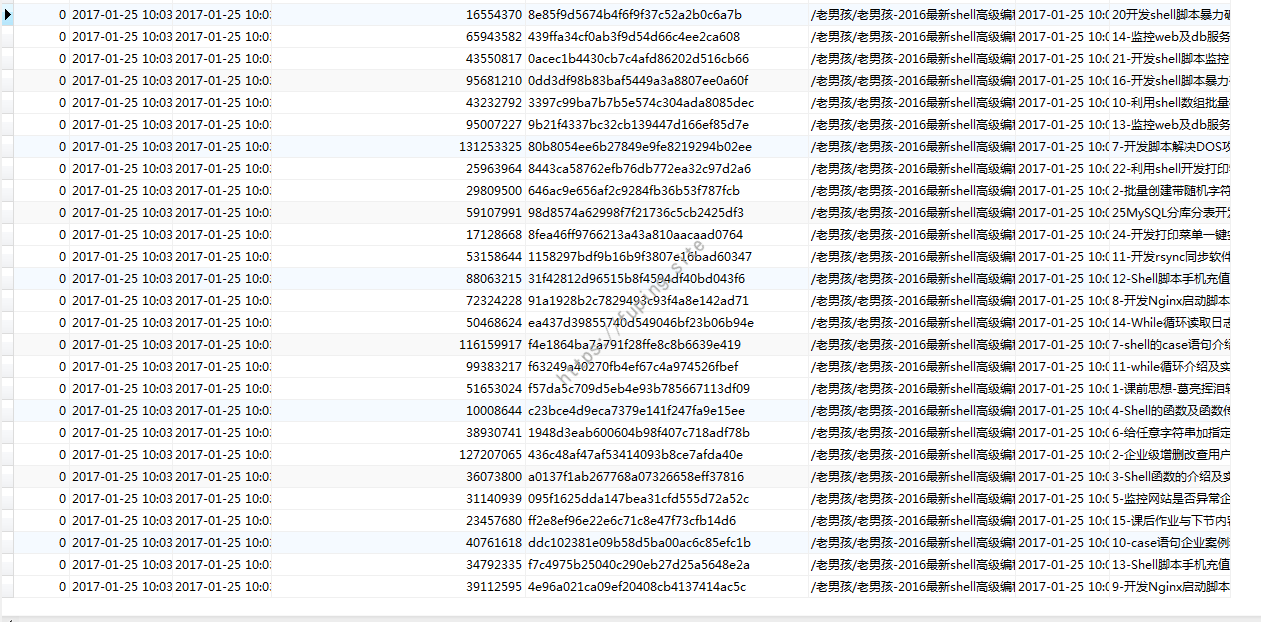
附上效果图
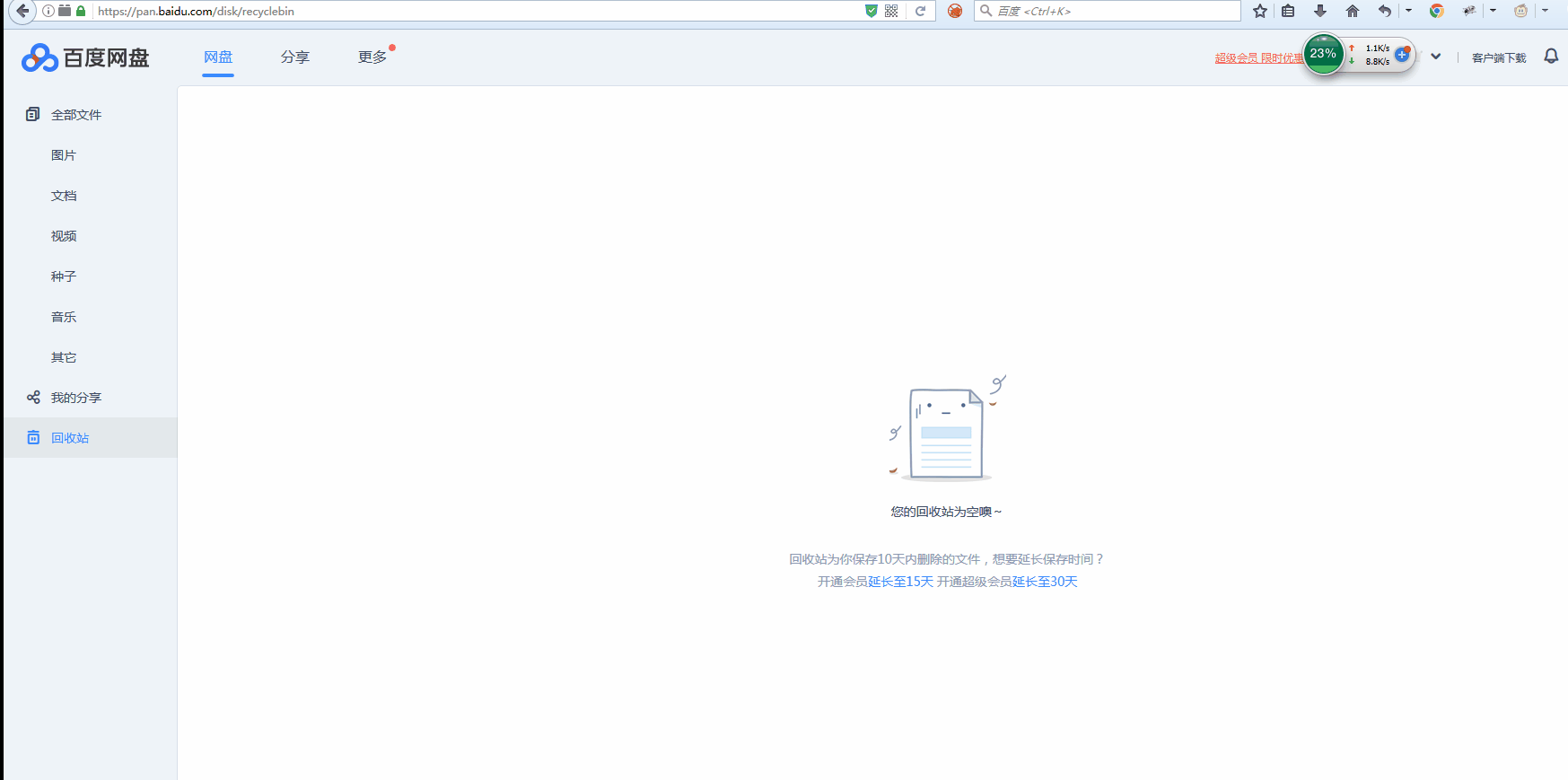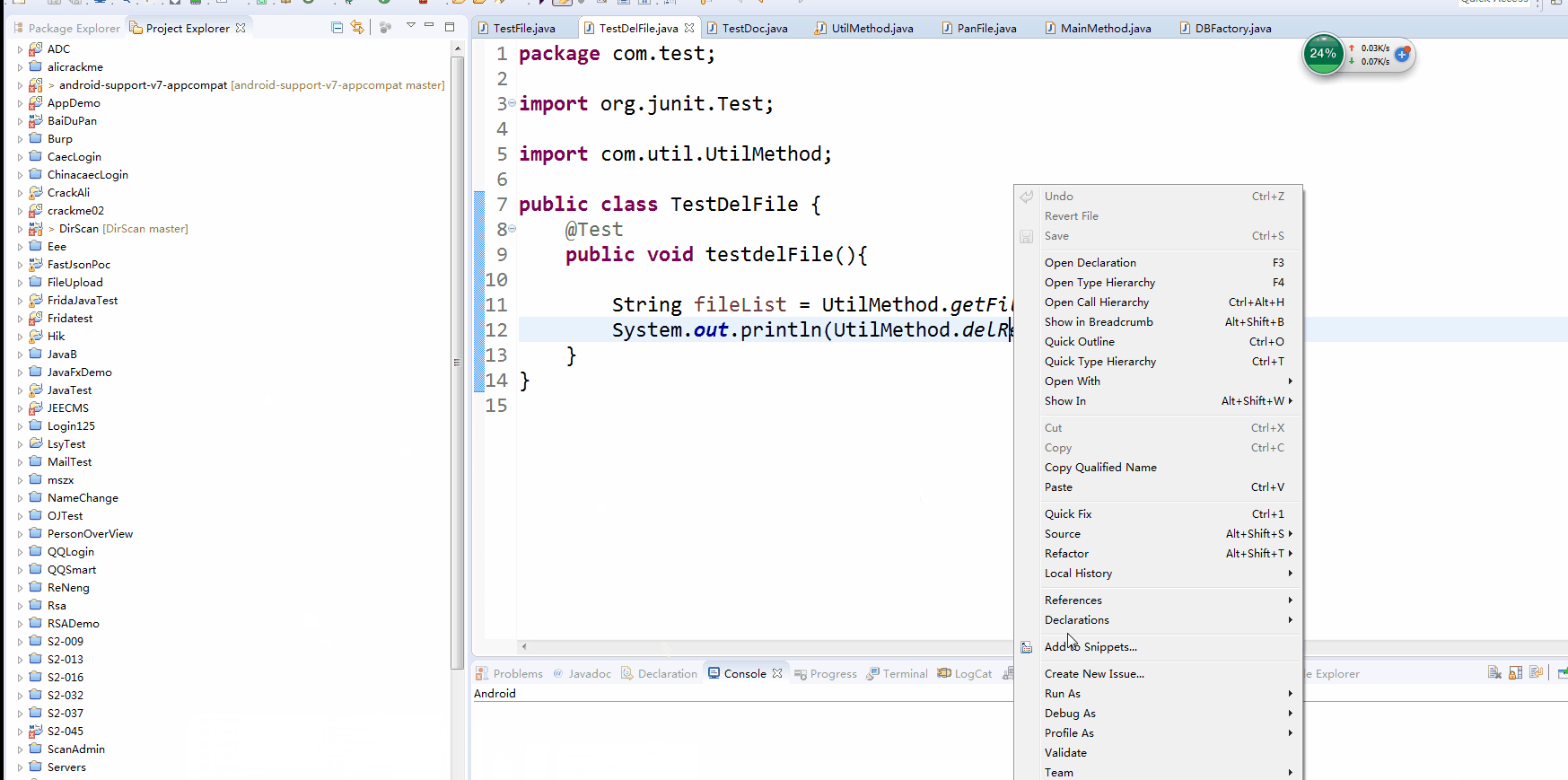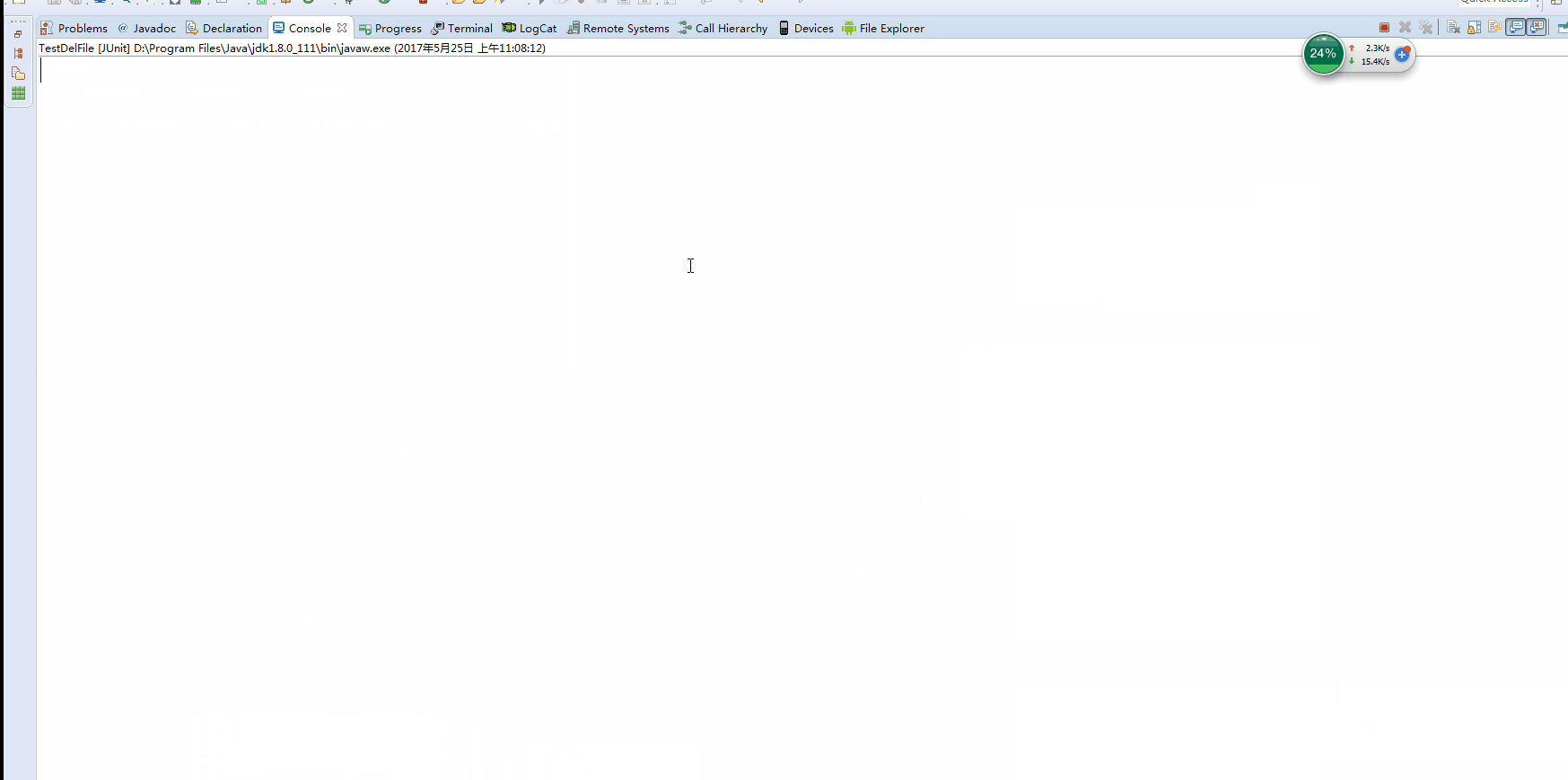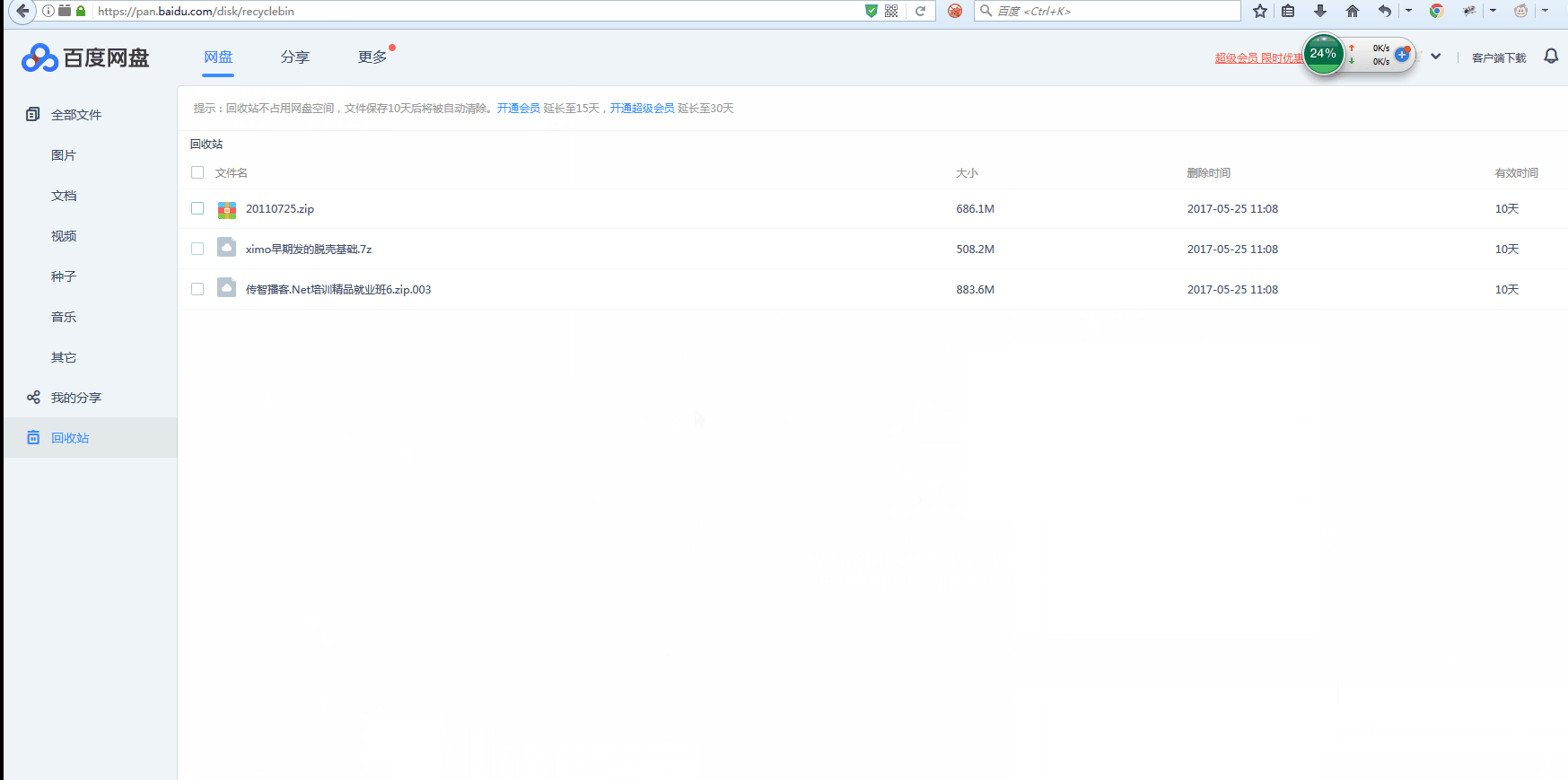
大功告成。不过删除的时候要注意一下,删除错误的话可以去回收站查看,然后再恢复。不要急于清除回收站。
代码仅供参考。代码地址:代码
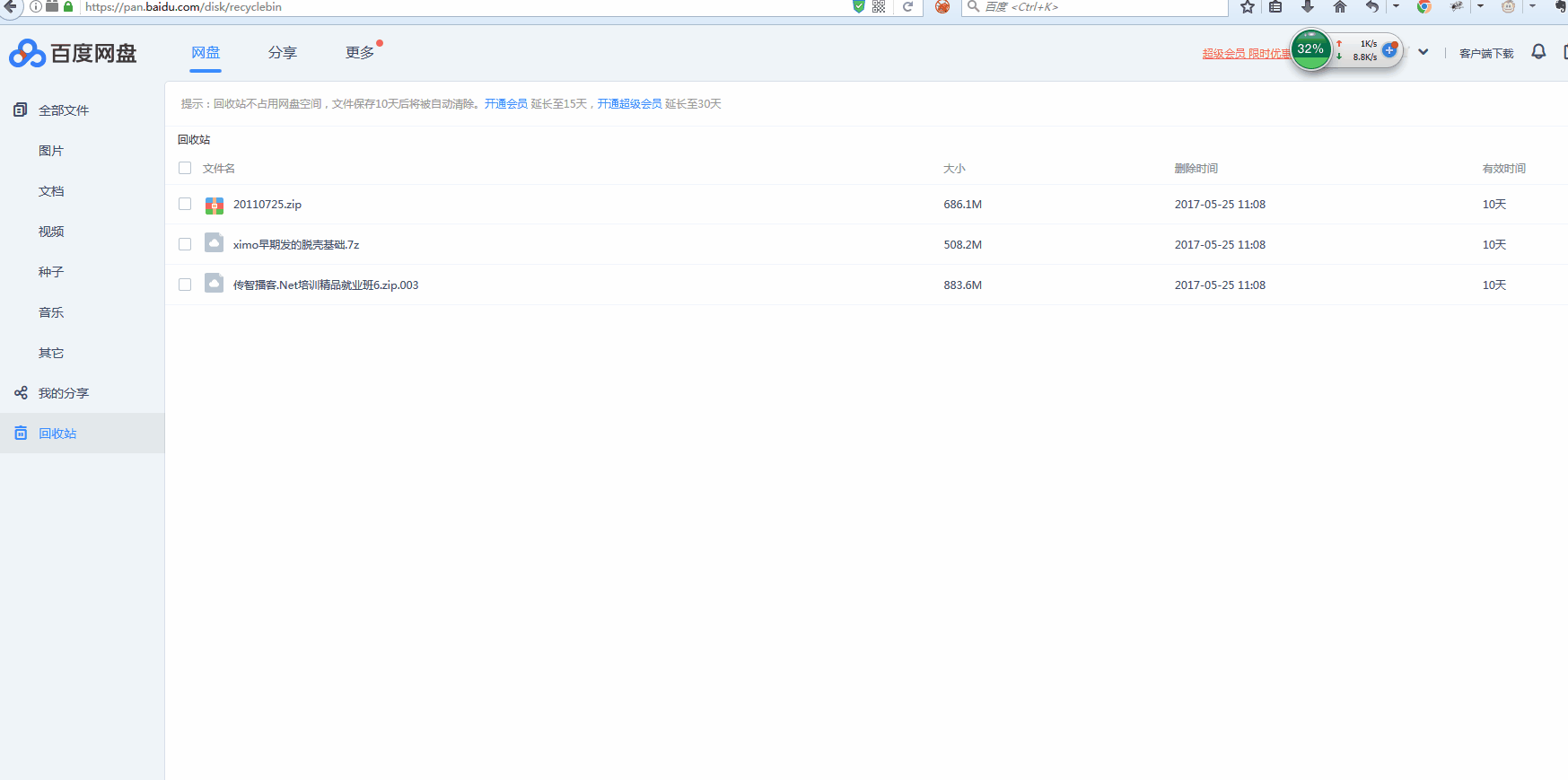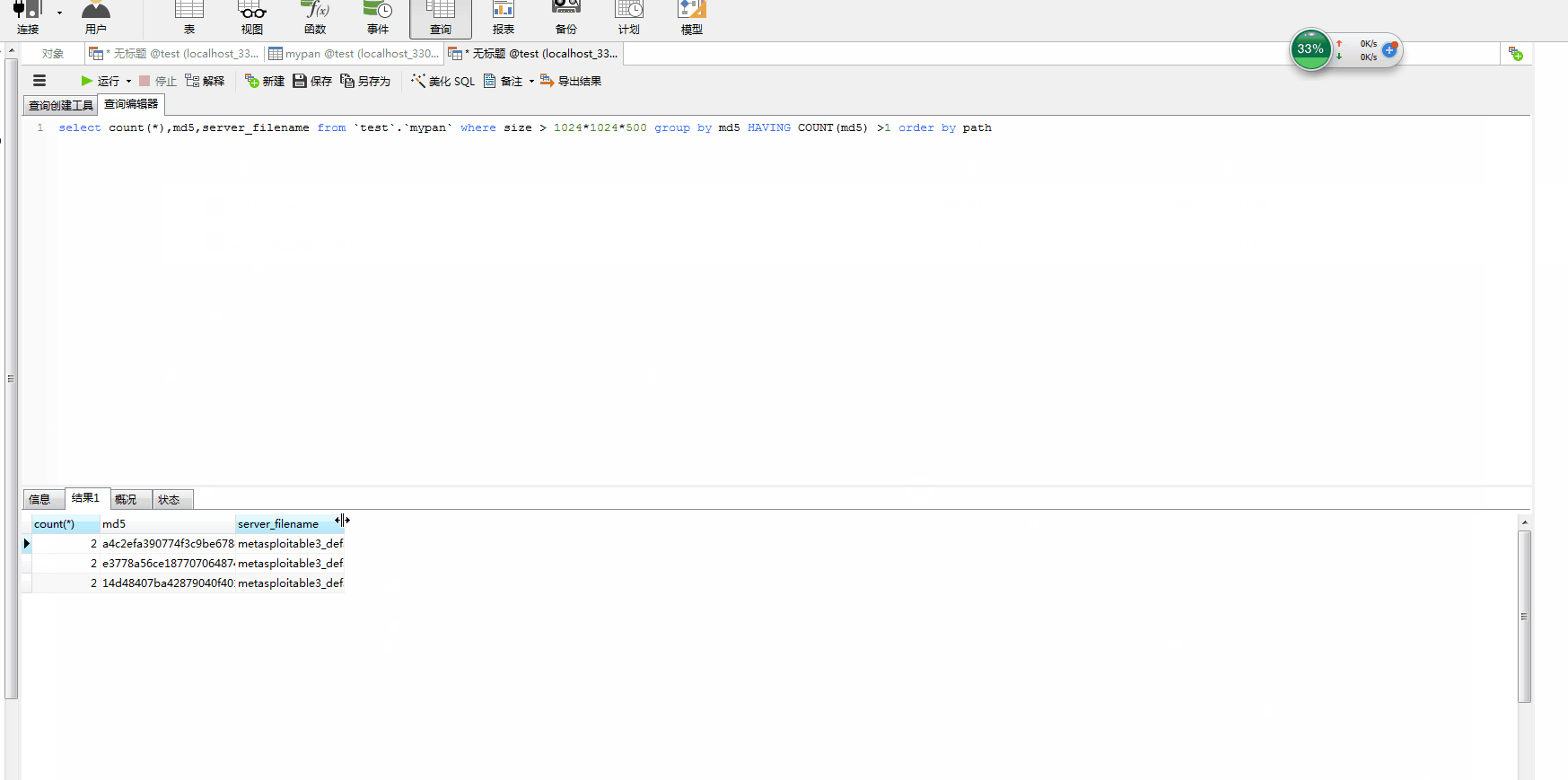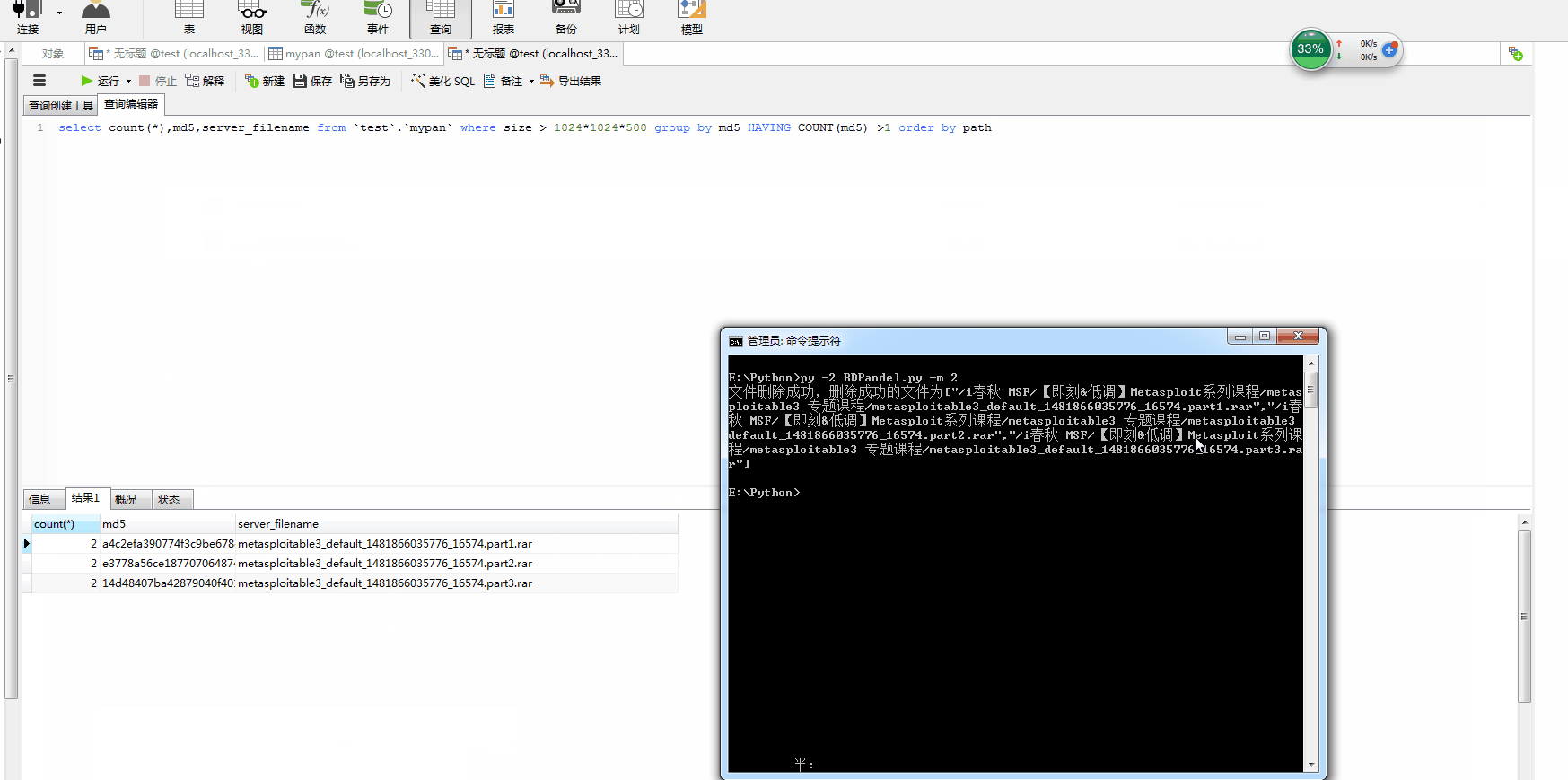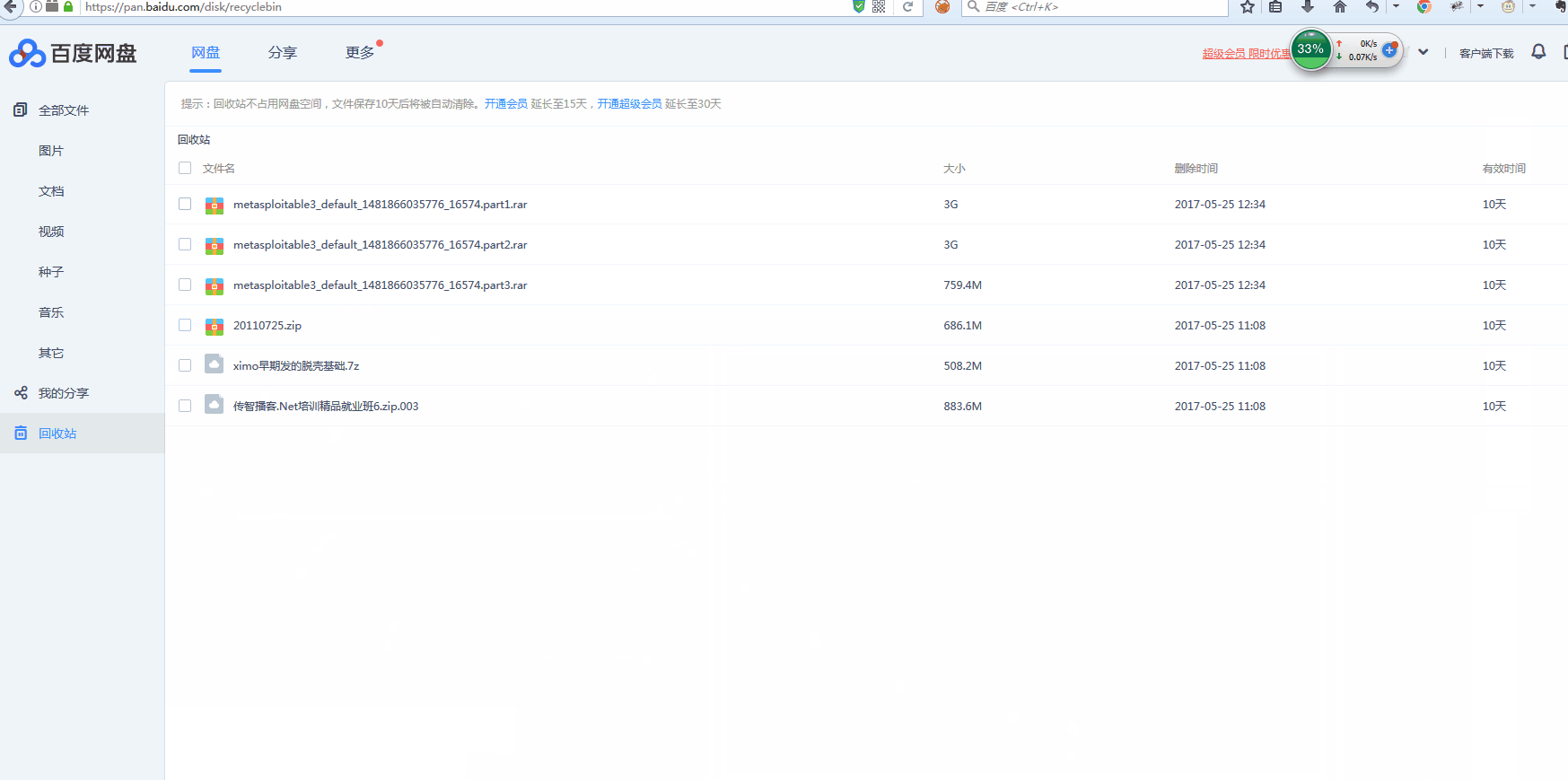
Python的实现脚本https://github.com/fupinglee/MyPython/blob/master/baidu/BDPandel.py 。
python代码删除文件效果图
还有一种最快的实现方法就是开个会员o(╯□╰)o。
0x03 总结
本文没有什么大的知识点,都是常用的内容拼接在了一起。主要用到了三方面的内容:
1.如何模拟网络请求抓取数据。这里采用了Java代码,Http请求采用了Jsoup。
2.JSON解析,使用了FastJSON来实现
3.递归遍历的实现
Python的实现也就是请求Http和数据库的操作。使用Python时要多注意数据类型和编码的转换。
